6 Session 5: Text Mining
6.1 내용정리
5.1 Introduction
- Text mining is one strategy for analyzing textual data archives that are too large to read and code by hand, and for identifying patterns within textual data that cannot be easily found using other methods.
- Text mining as a method can be used to conduct basic exploration of textual data, or can be used in combination with other methods like machine learning to predict group members’ future behaviors.
- This tutorial introduces text mining by outlining two basic methods for data exploration: generation of a concept list and generation of a semantic network.
- Learning the steps it takes to prepare, import, and analyze textual data for these simple procedures is enough to get started analyzing your own datasets.
- Most fundamentally, text mining is a methodology used to extract information, classify data, and identify patterns within textual datasets.
- Text mining can search through these large datasets for evidence of a factor of interest in seconds as opposed to the many hours it would take to manually search all of the transcriptions.
- Another benefit of text mining is its ability to perform data-driven discovery. Data-driven discovery is the process of looking for patterns within datasets without pre-conceived hypotheses regarding what the researcher expects to find.
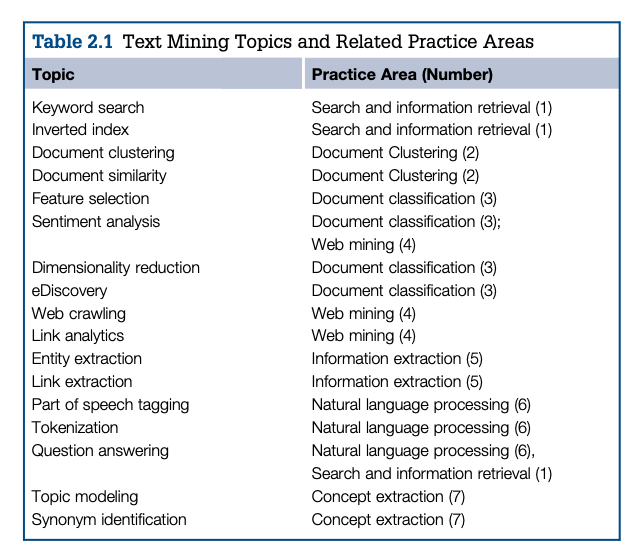
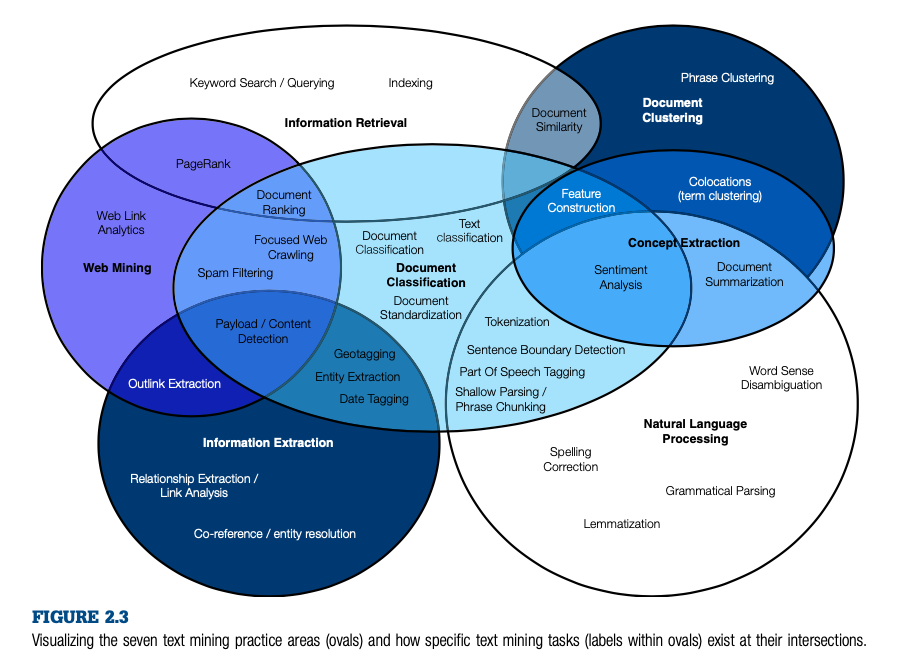
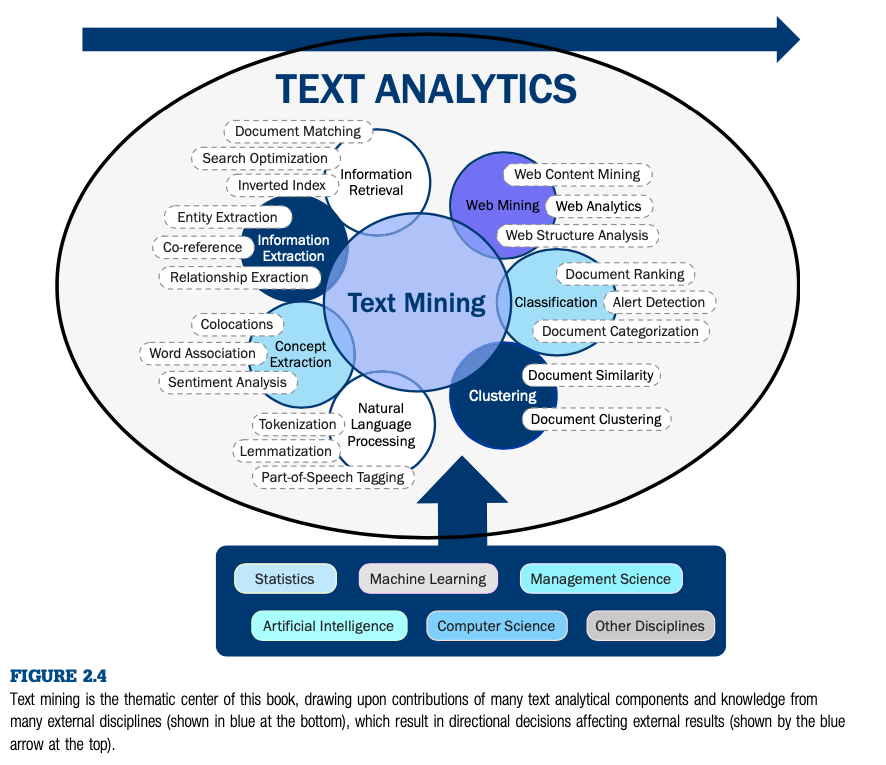
5.2 Overview of Text Mining
- Text mining as a method has some very specific assumptions built into it. The biggest assumption is certainly that individual words can have meaning even when they are far removed from their original context.
- Another common assumption of text mining is that frequently-occurring words within a text archive are more significant than infrequently occurring words.
- A third assumption of many text mining algorithms is that words that occur near each other in a text archive are related in some way.
5.3 Text Mining Tutorial
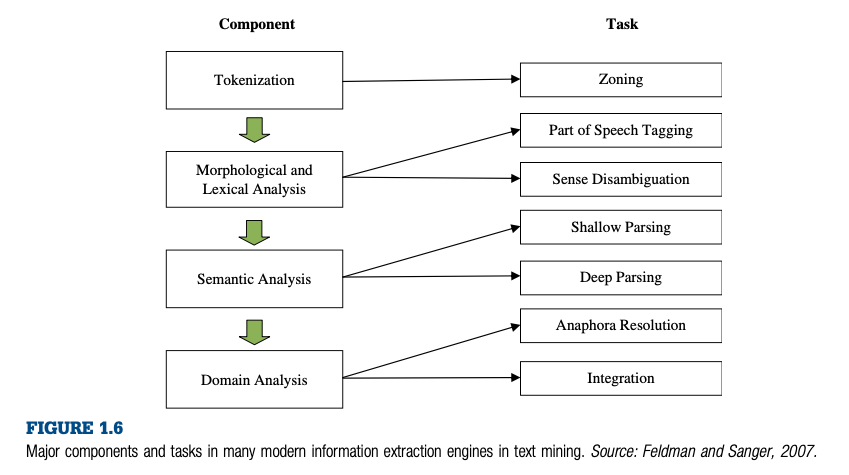
The overall process for conducting text mining is: (1) data collection, (2) data preparation, (3) pre-processing, (4) analysis, and (5) interpretation.
5.3.1 Data Collection
- Text mining was a useful method for this research project because the data collected by the team was unstructured textual data, meaning the data was in its naturally occurring form and not classified or organized into a database.
5.3.2 Data Preparation
- When using AutoMap and many other text mining tools, the file extension of the data file must be “.txt,” because the data must be contained within in a plain text file in order for the software to be able to read it.
5.3.3 Preprocessing
- Preprocessing is a term used to describe the cleaning up and standardizing of textual data prior to analysis. Two common types of preprocessing are stop word removal and stemming.
- Stop words are any words that would interfere in the software’s ability to identify meaningful patterns within the data.
- The second preprocessing technique, stemming, involves identifying the root of a word and then standardizing all the various endings that come after a root in order to avoid separate counts of a word that has different forms but the same meaning.
5.3.4 Data Analysis
- Text Corpus Statistics
- A concept list is a inventory list of the words that appear within a text corpus along with a count of each word’s frequency and other attribute information.
- Semantic Network Analysis
- Co-occurrence semantic networks are based upon two key notions: (1) the idea that words that exist close to each other within a textual dataset are likely related in some way, and (2) that the meaning of a text corpus can be analyzed by constructing a network that represents all of the relationships between words in a dataset simultaneously.
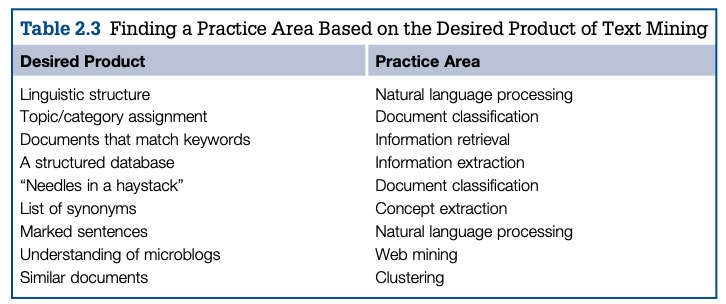
5.3.5 Interpretation
- Overall, the analyst’s goal during interpretation should be to: (1) identify patterns generated from the results, (2) confirm that these patterns are true representations of the original text corpus, and (3) interpret these patterns to explain what they represent or mean within the context of the dataset; how they answer a hypothesis or research question; how they can be explained using a theoretical framework; or how the patterns form the grounds for new theory development.
- Interpretation of the Medical Consultation Semantic Network Analysis.
5.4 Contributions
- Text mining was valuable in helping the researchers take this first step because it allowed them to conduct data-driven discovery in order to identify meaningful conversation topics without having to first develop hypotheses.
- The combined quantitative and qualitative results of this study are helping the researchers to build empirically-driven communication and organizational theory.
- Text mining is also useful for testing theories by looking for patterns within a text corpus to see whether they support existing theory.
- Additionally, theory can be used as a framework for gathering textual data or for interpreting the results of text mining.
- The way in which a dataset has been collected also greatly influences the success of text mining. Text mining is often described as an excellent method for analyzing very large text corpuses, but if the text contained within a very large dataset does not have very much in common, text mining is unlikely to identify any patterns, or if it does, the patterns may be more a function of word prevalence within a certain language or context and not due to the existence of important patterns within the data.
- Text mining is a very useful tool for both academic research and practical applications in business, education, and individual contexts. It can be used to help analysts learn more about the exponentially increasing text archives that are generated while we work, from online commenting and debates, through communication with friends and family, and during every online interaction and email we send.
6.2 더 읽어볼 자료
- Measureing semantic components in training and motivation (Arnulf, Dysvik, and Larsen 2019)
- Topic Modeling as a Strategy of Inquiry in Organizational Research- A Tutorial With an Application Exampleon Organizational Culture (Schmiedel, Müller, and Brocke 2019)
- 뇌와 인지모형 - 잠재의미분석을 사용한 문서분류 (김청택 and 이태헌 2002)
- 빅데이터를 이용한 심리학 연구방법 (김청택 2019)
- 잠재의미분석을 활용한 성격검사문항의 의미표상과 요인구조의 비교 (박성준, 박희영, and 김청택 2019)
ch5_10.png